Contrastive Language–Image Pretraining (CLIP) - Internals, Architecture, Training, and Limits
Published on Sunday, 17-08-2025
(Adopted from https://courses.opencv.org/)
CLIP, Explained (with PyTorch): Internals, Architecture, Training, and Limits
Contrastive Language–Image Pretraining (CLIP) links images and natural language at internet scale. Below I unpack each major concept in depth—what CLIP is, how contrastive learning works, what’s inside the model, why it trains the way it does, and where it struggles—sprinkled with practical PyTorch along the way.
1 What CLIP Is—and Why It Mattered
CLIP is a dual-encoder vision–language model trained on hundreds of millions of image, caption pairs scraped from the web. Instead of training on hand-labeled class datasets, CLIP learns a general notion of “what images and texts go together.” The payoff is zero-shot transfer: to classify an image, you don’t fine-tune—you describe candidate classes in natural language and pick the text whose embedding is closest to the image embedding.
Three ideas define CLIP:
- Multimodal: jointly learns from images + text.
- Internet scale: data contains enormous diversity, enabling broad visual understanding.
- Zero-shot: many downstream tasks require no additional training; you prompt with text.
2 Contrastive Learning: The Engine Under the Hood
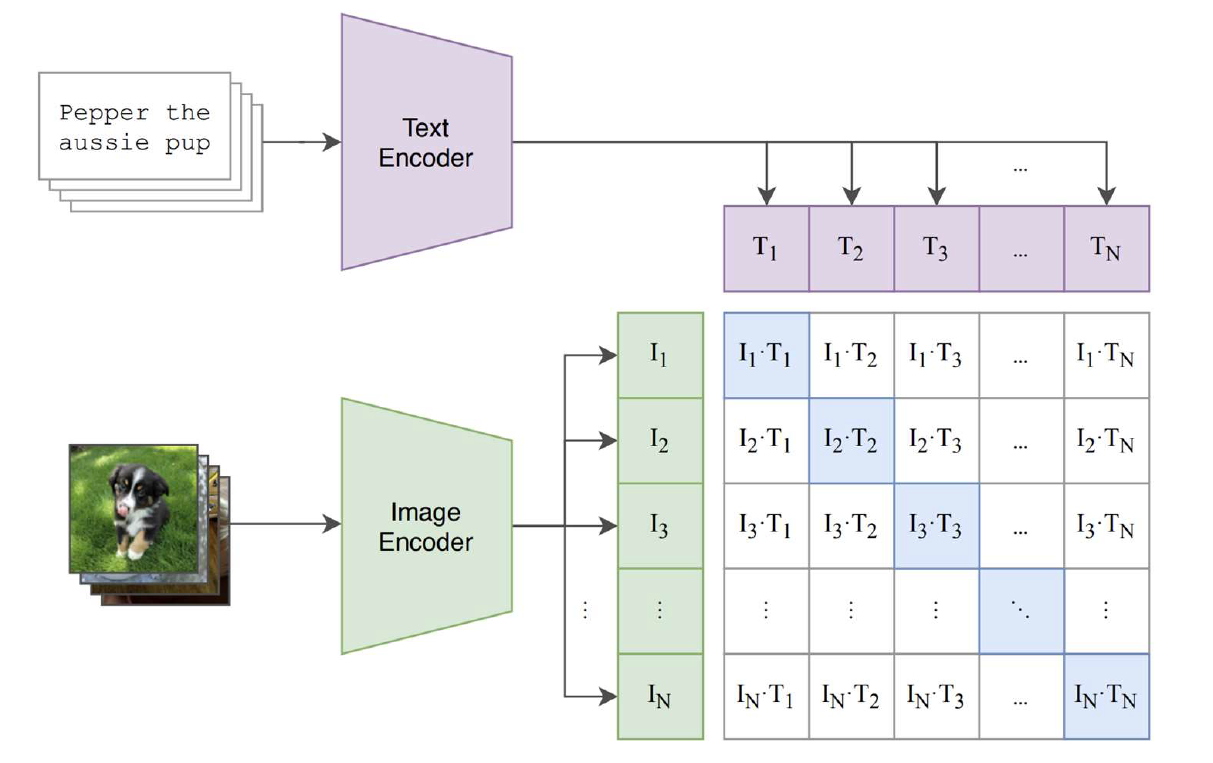
2.1 Shared Embedding Space
CLIP learns two encoders:
- a vision encoder that maps an image to a vector
- a text encoder that maps a caption to a vector
Training pushes matched pairs to have high cosine similarity, and mismatched pairs to be far apart. After training, images and texts that “mean the same thing” lie near each other.

2.2 In-Batch Negatives (Why Large Batches Help)
With a batch of image–text pairs, each image has 1 positive (its caption) and negatives (all other captions in the batch). Likewise for each text. The larger the batch, the richer the negative set—this is why CLIP uses very large effective batch sizes (tens of thousands with distributed training).
2.3 Symmetric InfoNCE Loss with Temperature
CLIP optimizes two cross-entropy terms:
- Image→Text: each image chooses its true caption among all captions in the batch.
- Text→Image: each caption chooses its true image among all images.
Let S = cosine(V, U) be the cosine similarity matrix between all image and text embeddings (after L2-normalization), and let τ be a learned temperature (logit scale). The logits are S / τ. The loss is:
mathcal{L} ;=;
rac{1}{2}
left(
\text{CE}ig(
rac{S}{\tau}, \text{diag}ig) + \text{CE}ig(
rac{S^\top}{\tau}, \text{diag}ig)
\right)- Why temperature? Smaller τ sharpens the softmax, encouraging confident alignment; τ is learned so the model sets its own hardness level.
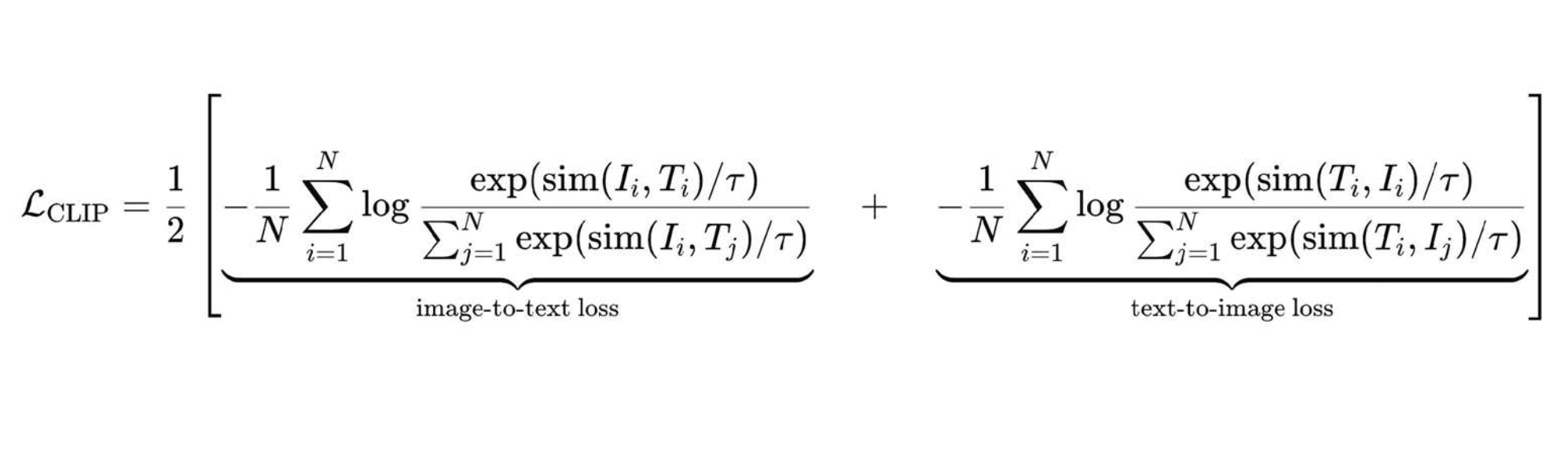
2.4 Minimal PyTorch for the Loss
import torch
import torch.nn.functional as F
def clip_loss(image_embeds, text_embeds, logit_scale):
# L2-normalize
image_embeds = F.normalize(image_embeds, dim=-1)
text_embeds = F.normalize(text_embeds, dim=-1)
# Similarity and temperature
logits = logit_scale * image_embeds @ text_embeds.t() # (B, B)
labels = torch.arange(logits.size(0), device=logits.device)
# Symmetric cross-entropy
loss_i = F.cross_entropy(logits, labels)
loss_t = F.cross_entropy(logits.t(), labels)
return (loss_i + loss_t) / 2
logit_scaleis typicallyexp(s)wheresis a learned scalar (commonly initialized aroundlog(1/0.07)).
3 CLIP’s Architecture (What’s Inside)
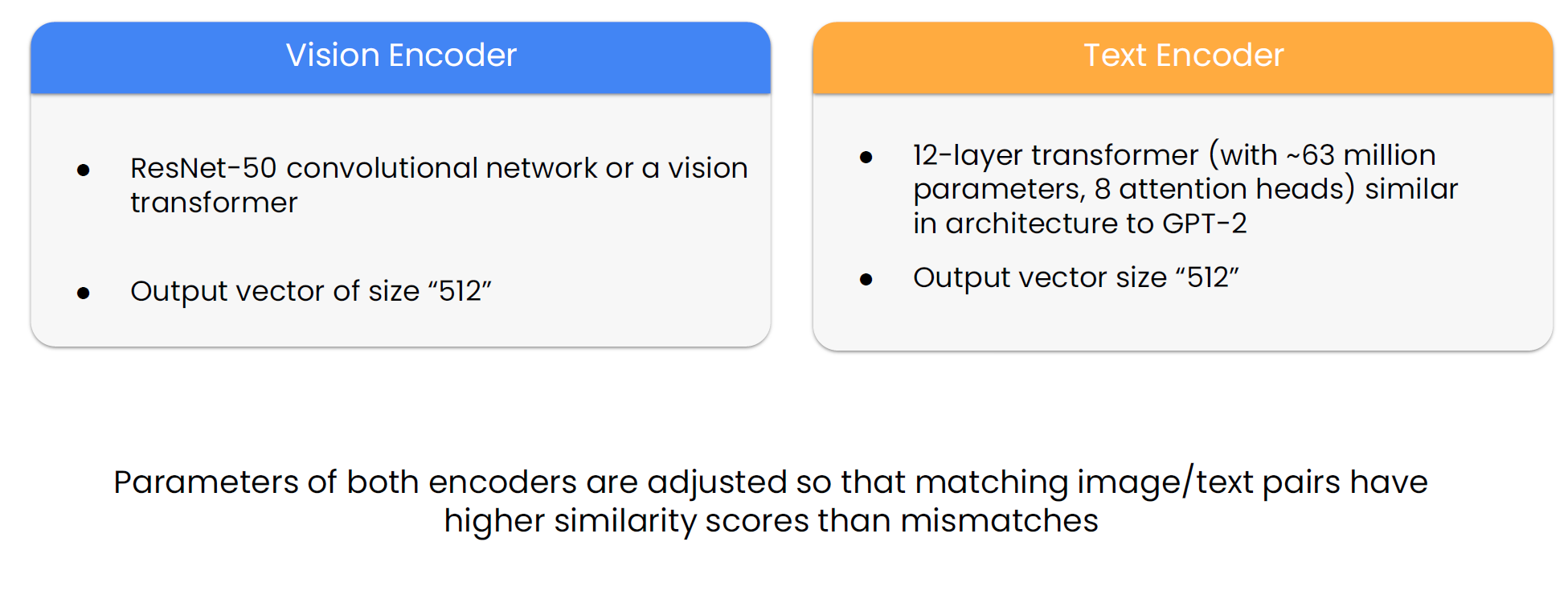
3.1 Two Encoders, One Space
- Vision encoder: a deep CNN (ResNet-50 variants up to RN50x64) or a Vision Transformer (e.g., ViT-B/32).
- Text encoder: a Transformer (≈12 layers, ~GPT-2-style) that produces a fixed-dimensional sentence embedding.
- Projection heads map both encoder outputs into the same dimensionality (commonly 512) before similarity.
A typical forward pass:
- Encode image → v
- Encode text → u
- Normalize, compute S = v u^T, apply temperature, compute symmetric cross-entropy.
3.2 Why Dual Encoders (vs. Generative Models)?
Early experiments showed contrastive learning is faster for learning useful visual features than training a generative model to predict each caption token from an image. You get strong representations quickly, and retrieval/classification emerge naturally from similarity.
3.3 Training Recipe (High Level)
- Initialization: Train from scratch (no ImageNet/GPT warm-starts).
- Batching: Massive effective batches (~32k+) using distributed data-parallel (DDP).
- Optimization: Adam/AdamW, cosine LR schedules are common; mixed precision speeds things up.
- Target: Minimize the symmetric contrastive loss above.
4 Data & Scale (Why It Generalizes)
- Data: Hundreds of millions of image–text pairs harvested from alt text/captions on the web (often referred to as “WIT”-style corpora).
- Diversity: Captions cover long-tail concepts and everyday language; this diversity fuels zero-shot transfer.
- Compute: The largest ResNet-based CLIP was trained for multiple days on hundreds of NVIDIA V100s; ViT variants trained somewhat faster at scale.
The big picture: more variety in images and natural language supervision produce embeddings that generalize surprisingly well—without task-specific labels.
5 Using CLIP for Zero-Shot in PyTorch
5.1 Quick Start with 🤗 Transformers
from transformers import CLIPModel, CLIPProcessor
from PIL import Image
import torch
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open("example.jpg")
labels = ["a photo of a cat", "a photo of a dog", "a photo of a hamster"]
inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
out = model(**inputs)
probs = out.logits_per_image.softmax(dim=-1)
pred_idx = int(probs.argmax())
print(labels[pred_idx], probs[0, pred_idx].item())Tips for better zero-shot:
- Prompt engineering: use descriptive templates (“a photo of a label”, “a close-up of a label, etc.).
- Ensembling: average text embeddings across multiple templates per label.
5.2 Text–Image Retrieval (Both Directions)
# Suppose you have a batch of images and many candidate texts
B = 8
texts = ["a sunrise over mountains", "a red sports car", "a tabby cat", "..."]
inputs = processor(text=texts, images=[image]*B, return_tensors="pt", padding=True)
with torch.no_grad():
out = model(**inputs)
sim = out.logits_per_image # (B, len(texts)) similarity
topk = sim.topk(k=3, dim=1).indices # top-3 texts per image6 From-Scratch (Toy) CLIP in PyTorch
Below is a didactic, simplified CLIP to show how pieces fit together. It’s not production-quality, but it’s useful for understanding—and it trains on your own image, caption pairs.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet18
class TextTower(nn.Module):
def __init__(self, vocab_size, d_model=512, n_layers=6, n_heads=8, max_len=77):
super().__init__()
self.token = nn.Embedding(vocab_size, d_model)
self.pos = nn.Embedding(max_len, d_model)
enc_layer = nn.TransformerEncoderLayer(d_model, n_heads, dim_feedforward=2048, batch_first=True)
self.encoder = nn.TransformerEncoder(enc_layer, n_layers)
self.proj = nn.Linear(d_model, d_model)
def forward(self, tokens):
# tokens: (B, T) int64
B, T = tokens.shape
x = self.token(tokens) + self.pos(torch.arange(T, device=tokens.device))[None, :]
x = self.encoder(x) # (B, T, d)
x = x[:, -1] # use last token (or pool)
x = self.proj(x) # (B, d)
return x
class VisionTower(nn.Module):
def __init__(self, out_dim=512):
super().__init__()
self.backbone = resnet18(weights=None)
self.backbone.fc = nn.Identity()
self.proj = nn.Linear(512, out_dim)
def forward(self, images):
x = self.backbone(images) # (B, 512)
x = self.proj(x) # (B, d)
return x
class TinyCLIP(nn.Module):
def __init__(self, vocab_size, d_model=512):
super().__init__()
self.visual = VisionTower(d_model)
self.text = TextTower(vocab_size, d_model)
self.logit_scale = nn.Parameter(torch.log(torch.tensor(1/0.07)))
def forward(self, images, tokens):
v = F.normalize(self.visual(images), dim=-1) # (B, d)
u = F.normalize(self.text(tokens), dim=-1) # (B, d)
logit_scale = self.logit_scale.exp()
logits = logit_scale * v @ u.t() # (B, B)
return logitsTraining loop (sketch):
def train_step(model, images, tokens, optimizer):
model.train()
logits = model(images, tokens)
labels = torch.arange(logits.size(0), device=logits.device)
loss = (F.cross_entropy(logits, labels) + F.cross_entropy(logits.t(), labels)) / 2
optimizer.zero_grad()
loss.backward()
optimizer.step()
return float(loss)For realistic performance: switch the vision tower to a ViT (e.g.,
timm), increase depth/width/layers, adopt mixed precision, DDP, cosine LR, AdamW, gradient checkpointing, and a fast tokenizer for the text tower.
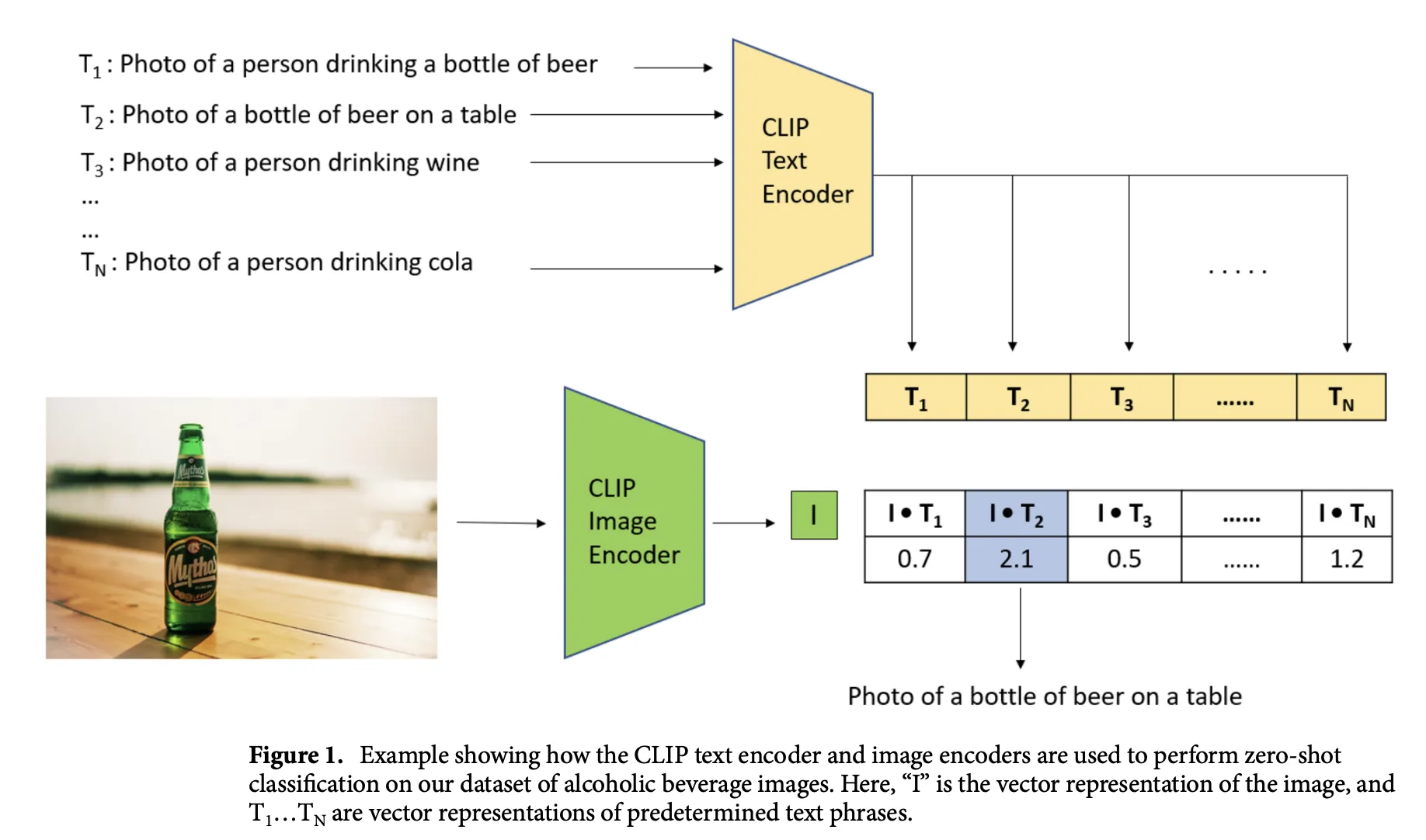
7 Why Zero-Shot Works (Intuition)
- Language is a universal interface. Text prompts express tasks without retraining.
- Contrastive learning aligns modalities. If “a red balloon in foggy mountains” and its image land near each other, then unseen images of red balloons will land near that text too.
- Scale reduces overfitting to narrow domains. Broad web data forces the model to capture general semantics, not just specific class taxonomies.
(_from https://www.marktechpost.com/wp-content/uploads/2023/07/Screenshot-2023-07-27-at-9.49.40-PM.png)
{kind=link}
8 Practical Engineering Notes (PyTorch)
Normalization matters: always L2-normalize embeddings before similarity.
Temperature as a parameter: learn it; don’t fix it.
Large negatives: use DDP to accumulate large effective batches (e.g., gradient accumulation).
Precision/speed: AMP (
torch.cuda.amp) dramatically speeds training and reduces memory.Evaluation
- Zero-shot classification: top-1/top-5 accuracy using prompt templates.
- Retrieval: Recall\@K for text→image and image→text.
Prompt ensembling: average over multiple textual templates per class; it’s a cheap win.
9 Where CLIP Struggles (and What to Do)
Abstract & fine-grained tasks Counting, distances, or distinguishing near-identical subcategories (e.g., bird species) are tough in pure zero-shot. Mitigations: add few-shot adapters (LoRA), train a linear probe, or fine-tune on labeled data.
Out-of-distribution (OOD) gaps Domains unlike web images (e.g., medical scans, handwriting) degrade performance. Mitigations: domain-specific fine-tuning or adapters; specialized prompts.
Prompt sensitivity Small wording changes can swing predictions. Mitigations: templates, ensembling, calibration (e.g., class-conditional normalization).
Biases from web data & ethics Models inherit stereotypes present in captions and can behave unreliably in sensitive scenarios. Mitigations: bias auditing, safer prompt sets, human oversight, avoid misuse (e.g., surveillance).
10 Beyond Zero-Shot: Fine-Tuning Paths
- Linear probe: freeze encoders; train a small classifier on top of image embeddings.
- Prompt tuning: learn continuous prompt vectors instead of hand-written text.
- LoRA/adapters: inject low-rank trainable layers; keep base weights mostly frozen.
- Distillation: compress a large CLIP into a smaller, faster student model.
PyTorch makes all of the above straightforward: treat encoders as frozen backbones, attach your module, and optimize only the new parameters.
11 A Minimal End-to-End Training Sketch (Images + Captions)
from torch.utils.data import Dataset, DataLoader
class PairDataset(Dataset):
def __init__(self, image_paths, captions, tokenizer):
self.paths = image_paths
self.caps = captions
self.tok = tokenizer # returns tensor ids (BPE/WordPiece/etc.)
def __len__(self): return len(self.paths)
def __getitem__(self, i):
img = load_and_preprocess_image(self.paths[i]) # (3,H,W), normalized
ids = self.tok(self.caps[i]) # (T,)
return img, ids
# Setup
model = TinyCLIP(vocab_size=tokenizer.vocab_size, d_model=512).cuda()
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4, weight_decay=0.2)
for epoch in range(num_epochs):
for images, tokens in loader:
images, tokens = images.cuda(), tokens.cuda()
logits = model(images, tokens)
labels = torch.arange(logits.size(0), device=logits.device)
loss = (F.cross_entropy(logits, labels) + F.cross_entropy(logits.t(), labels)) / 2
optimizer.zero_grad()
loss.backward()
optimizer.step()Notes
- Replace
TinyCLIP’s vision tower with a ViT (e.g., viatimm.create_model("vit_base_patch32_224", pretrained=False)and a projection head). - Use a real tokenizer (e.g., sentencepiece/BPE) and pad/pack sequences properly.
- Add AMP (
torch.cuda.amp.autocast+GradScaler) and DDP for scale.
Closing Thoughts
CLIP popularized a wonderfully pragmatic idea: learn a shared space for images and texts using contrastive alignment at web scale, then prompt that space to do useful things. With a clean loss, dual encoders, and big diverse data, you get powerful zero-shot behavior—plus a foundation you can fine-tune for anything else.
If you’d like, I can package the toy CLIP into a small training repo (data module + tokenizer + DDP script + evaluation) or tailor a fine-tuning path for your dataset.